2023-2024中国排球超级联赛保定赛区购票入口
2023-10-30
更新时间:2023-09-30 16:08:58作者:无忧百科


新智元报道
编辑:LRS
【新智元导读】DALL·E 3让我们看到了生成+理解的大语言模型的魔力。就在其发布的同一天,国内的一个新工作引起了社区的关注:DreamLLM。DreamLLM实现了协同学习的多模态理解和生成的大一统,能端到端进行生成和理解,这是否有望成为未来「DALL·E 4」的技术路线?
想象一下,如果AI已经能够帮助你完成一个图文并茂的文档,而不是仅有文字部分的内容,你会拿来干什么?
例如,问问自己假期想去的旅游城市是什么样的?

或者聊聊自己喜欢的电影?

或者,你只需要你的大语言模型用图片给你展示一些你想象中的画面?(文生图)
an astronaut riding a horse in a photorealistic style/in the style of Pop Art/as a charcoal sketch/as a golden relief.
一位宇航员骑着一匹马的真实照片/波普艺术风格画(Pop Art)/炭笔素描/金色浮雕。

robots meditating in a vipassana retreat.
机器人在观禅闭关中冥想。

Downtown Istanbul/Austin/Beijing/LA at sunrise. detailed ink wash.
日出时的伊斯坦布尔/奥斯汀/北京/洛杉矶。详细的水墨画。

Oil-on-canvas painting of a blue night sky with roiling energy. A fuzzy and bright yellow crescent moon shining at the top. Below the exploding yellow stars and radiating swirls of blue, a distant village sits quietly on the right. Connecting earth and sky is a flame-like cypress tree with curling and swaying branches on the left. A church spire rises as a beacon over rolling blue hills.
油画作品,描绘了一个蓝色夜空中翻滚的能量。顶部有一轮模糊而明亮的黄色新月在闪耀。在爆炸的黄色星星和辐射着蓝色涡旋下方,一个遥远的村庄静静地坐落在右侧。连接大地和天空的是一棵像火焰般的柏树,在左侧卷曲摇摆着枝干。教堂尖塔高耸于起伏的蓝山之上,像一个灯塔。

这些结果来自于国内研究人员的最新研究DreamLLM,全新的多模态生成理解统一大模型。能生成能理解,图文并茂的内容也可以生成了!

论文地址:https://arxiv.org/abs/2309.11499
项目地址:https://dreamllm.github.io/
GitHub:https://github.com/RunpeiDong/DreamLLM
诸如DALL·E 3、Midjourney此类文生图模型,是否能对多模态大语言模型的理解起到帮助呢?在这篇论文中,研究人员提出了「协同多模态生成和理解」,即生成能够帮助理解,理解也能帮助生成。
正如费曼在1988年去世之前写在他的办公室黑板上的名言:「What I cannot create, I do not understand」。

这句话的含义是说,如果你不能创造一个东西,那么你就无法真正理解它。
费曼相信,真正的理解源于能够从头构建或重建某事物的能力。这是他的科学哲学的一个核心部分,也是他作为一位教师和科学家的教学方法的基础。
技术介绍
DreamLLM的模型作为一个多模态大语言模型,包含一个大语言模型逻辑核心、多模态输入编码器和数据生成解码器,其设计思想主要遵循两大原则:
生成一切
与生成中间图像语义表示(如CLIP嵌入)的现有工作不同,在训练过程中,DreamLLM不仅将所有模态的原始数据作为输入,而且以真正端到端的方式将其作为输出。其中的挑战在于使多模态大语言模型能够学习图像后验而不损害其理解能力。
为了解决这个问题,作者引入了可学习嵌入集合「dream queries」,这些嵌入封装了由多模态大语言模型编码的语义信息。这种方法避免了改变多模态大语言模型的输出空间。
然后,原始图像通过基于这些语义作为生成条件的Stable Diffusion扩散图像生成解码器进行解码生成。
通过预训练Stable Diffusion充当得分函数(「score function」),直接在像素空间中对图像后验进行建模,并借助得分蒸馏实现直接采样。
图文交错文档的生成式预训练(Interleaved-GPT, I-GPT)
DreamLLM经过训练,可以使用互联网上图文交错的多模态语料库进行生成式预训练,既编码又解码交错的图文多模态输入。
与现有方法中将多模态输入进行编码不同,解码交错的多模态输出具有挑战性,因为它涉及复杂的交错布局结构和对图像的长期上下文要求。
作者使用一个独特的标记来处理交错布局学习,该标记预测了图像在文本中的位置。利用DreamLLM大语言模型的因果关系特性,所有内容都是根据任意长度的历史多模态上下文生成的。
这种交错生成预训练(I-GPT)固有地形成了文档中图像和文本的所有联合、边际和条件分布,并导致了一种学习协同作用,在创造中促进使DreamLLM的理解,反之亦然。
下面这张图可以直观的看出DreamLLM和现有图文多模态大模型的差异:
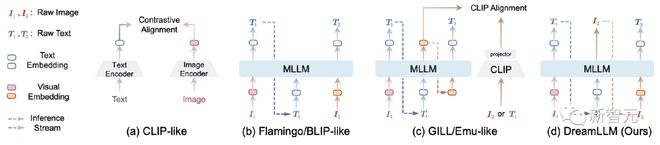
(a)类似于CLIP的模型一般使用双塔结构明确对齐图文语义表示。
(b)类似于Flamingo/多模态大语言模型将图文表示编码至统一的流形空间。然而,这些模型缺乏完全自回归性能力,因为它们只输出语言。
(c)另一类工作将视觉输出与CLIP表示进行对齐,但此对齐发生在一个中间语义空间而不是原始数据空间。由于固有的模态差距,CLIP语义主要关注「共享模态知识」,往往忽视了可能增强多模态理解的「特定模态知识」。
另外,根据信息瓶颈理论,CLIP学习的图文「不变性」(invariance知识)目标会导致大量信息的丢失。
对齐CLIP也会导致像Emu这样的模型生成原始图像需要进行第二阶段扩散图像生成模型的微调,这些模型也无法生成原始的图文并茂的文档。
(d)相比较而言,DreamLLM以统一自回归方式生成原始语言和图像输入,实现了图文信号的完全自回归建模,因此天然支持图文并茂的文档生成。
实验结果
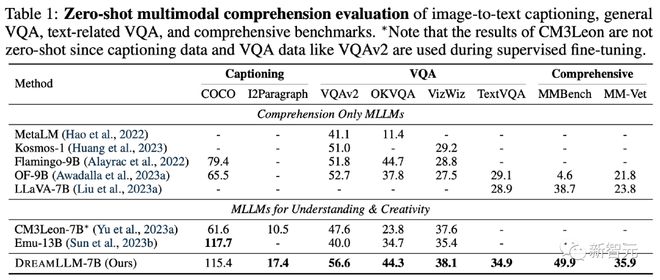
DreamLLM在多项零样本多模态图文理解和生成任务上取得先进的效果。
零样本多模态理解(文+图-> 文)
零样本文生图(文->图)

零样本in-context(上下文)图像编辑

零样本subject-driven(主体驱动)图像生成

零样本物体组合生成(文+图->图)

多模态上下文理解是多模态大语言模型的一个关键新兴能力。
虽然在上下文视觉问答方面已经取得了重大进展,但在上下文图像生成方面仍相对不足。DreamLLM的多模态上下文条件图像合成能力如上图所示,为该领域提供了有希望的见解。
然而,零样本上下文图像编辑、主题驱动的图像生成和组合式生成等任务中仍存在显著挑战,特别是没有像DreamBooth中的下游微调或Prompt2Prompt中的注意力修改技术。
尽管存在这些障碍,DreamLLM根据提供的图像上下文生成图像的能力。这种能力表明DreamLLM在保持主题、身份和语义上下文方面具有潜在的前景,从而为解决这些复杂任务铺平了一条新路。
多模态对话样例(文+图->文+图)
艺术和生活:

动物:

文字:

人文:

对比GPT-4


结论与讨论
DreamLLM首次实现了大语言模型LLM的具有协同促进作用的多模态内容创作和理解的学习,充分探索了多模态理解和生成的协同效应。
通过在多模态原始数据空间采样进行完全的自回归建模,在大量极易获取的互联网图文混排数据上训练,激发出诸如图文交互对话、图文并茂文档的自由生成、文生图、零样本subject-driven image generation等多模态理解和生成任务。
对比DALL·E 3的ChatGPT和生成的组合系统方案,DreamLLM迈向了更进一步的端到端学习,展现出未来可能超越DALL·E 3的巨大潜力。
当然,我们离人类水平的智能还有很长的距离。对于生成模型存在偏见、安全性和滥用问题也引起了关注,但是像DreamLLM这样的框架为未来更具能力和合作性的AI助手指明了方向。
该项工作对关键点是在图像和文本中共同训练生成能力可以带来更出色的理解力和创造力。
随着AI不断跨越多种形式,找到感知、推理和创作之间的协同效应将开辟前进之路。
这种多模态生成模型对我们与人工智能系统的互动方式可能具有革命性的影响。
想象一下,你可以要求个人助理不仅描述一个概念,还可以生成或编辑一张图片来说明它,或者通过描述而不是关键词在互联网上搜索媒体内容,实现视觉和语言的流畅共同理解和生成是迈向更自然、直观的人机交互的基石。
参考资料:
https://dreamllm.github.io/
