中国排球超级联赛保定第一阶段赛程安排一览
2023-10-30
更新时间:2023-10-08 14:08:55作者:无忧百科

梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
传奇程序员卡马克(John Carmack),与强化学习之父萨顿(Richard Sutton)强强联手了,All in AGI。
2030年向公众展示通用人工智能的目标是可行的。
并且与主流方法不同,不依赖大模型范式,更追求实时的在线学习。

两人在萨顿任教的阿尔伯塔大学机器智能研究所(Amii)特别活动上宣布了这一消息。
萨顿会加入卡马克的AI创业公司Keen Technologies,同时保持在阿尔伯塔的教职。
两人在活动中都承认,与拥有成百上千员工的大公司相比,Keen Technologies的团队规模很小。
目前还在刚起步阶段,公司整个技术团队都到了现场——
只有站着的这4个人。

其融资规模2000万美元,与OpenAI、Anthropic这样动辄几十亿的也没法比。
但他们相信,最终AGI的源代码是一个人就能编写的量级,可能只有几万行。
而且当前AI领域正处在杠杆效应最大的特殊时刻,小团队也有机会做出大贡献。
传奇程序员与强化学习之父
卡马克的传奇经历,从开发世界第一款3D游戏,到转型造火箭,再到加入Oculus成为后来Meta VR关键人物的故事都已被人熟知。
后来他与AI结缘,还和OpenAI有关。
他曾在另一场访谈中透露,Sam Altman曾邀他加入OpenAI,认为他能在系统优化方面发挥重要作用。
但卡马克当时认为自己对机器学习范式的现代AI没有任何了解,也就没有答应。
这却成了他开始了解AI的一个契机。

他向OpenAI的首席科学家Ilya Sutskever要了一个入门必读清单,从头开始自学,先对传统机器学习算法有了基本的了解。
等有了空闲,打算继续涉足深度学习的时候,他来了个一周编程挑战:
打印几篇LeCun的经典论文,在断网情况下动手实践,从推反向传播公式开始。
一周过去后,他带着用C++手搓的卷积神经网络结束闭关,没有借助Python上的现代深度学习框架。
只能说佩服大神了。

此时他的主业还是在Facebook(后改名Meta)旗下Oculus研究VR,带领团队推出了Ouclus Go和Quest等产品。
不过这个过程中,他与公司管理层之间也逐渐产生矛盾和分歧,认为公司内部效率低下,也曾公开发表不满。

2019年,他辞去Oculus CTO职位转而担任“顾问CTO”,开始把更多精力转向AI。
2022年8月,他宣布新AI创业公司Keen Technologies宣布融资2000万美元,投资者包括红杉资本,GitHub前CEO Nat Friedman等。
后续他也透露,其实区区2000万美元,自己就拿得出手。
但是从别人那里拿钱能给他一种危机和紧迫感,有更强烈的决心把事情做好。

2022年底,他正式离开Meta,并将VR视为已经过去的一个人生阶段,接下来完全转向AI。
除了这条明面上的主线之外,卡马克与AI还有一些莫名的缘分。
当年他的3D游戏激发了对图形计算的需求,GPU也是从游戏领域开始发展壮大。
到如今正是GPU的算力支持了AI的爆发,他谈到这些时仍为自己的贡献感到自豪。
今天的另一位主角萨顿也同样是位传奇人物。
他被誉为强化学习之父,为强化时间差异学习和策略梯度等方法做出重要贡献,也是强化学习标准教科书的合著者。
2017年他以杰出科学家身份加入DeepMind,参与了AlphaGo系列研究,他的学生David Silver则是AlphaGo主要负责人之一。

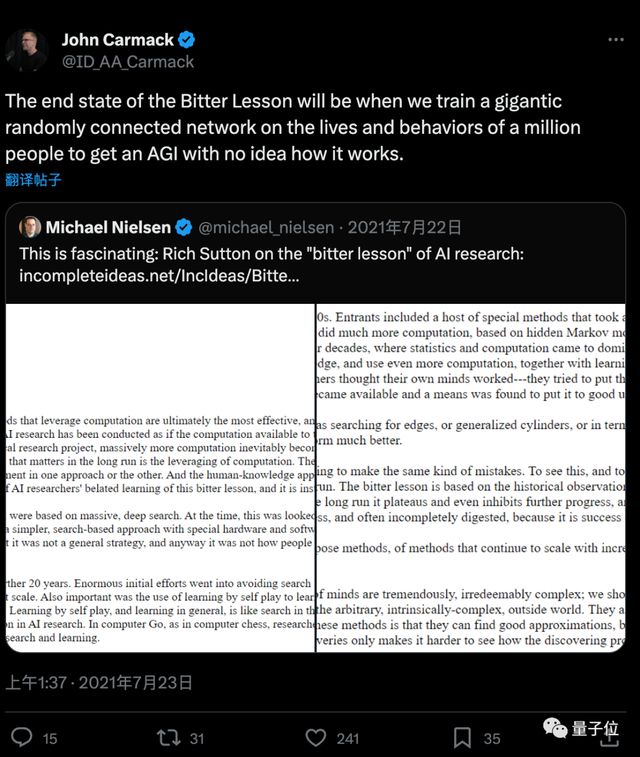
萨顿写过一篇著名短文The Bitter Lesson,认为试图把人类经验教给AI是行不通的,至今为止所有突破都是依靠算力提升,继续利用算力的规模效应才是正确道路。
两人正式交流之前,卡马克就曾表达过对这篇文章的关注和认同。
但两人真正直接交流,是萨顿主动联系的。
几个月前,卡马克宣布AGI创业公司融资之后,收到了萨顿的邮件。
萨顿想要问他他在研究的道路上应该走纯学术、商业化还是非盈利组织路线的问题。
但在后续邮件交流中,两人发现在AI研究方向和理念上存在惊人的一致性,渐渐确立了合作关系。
具体来说,两人达成了4个共识:
不只依赖大模型,小团队也有机会
很大胆的目标,现场观众也是这么认为的。
面对“小团队如何搞定这么宏大的目标”的提问,卡马克认为实现AGI所需的数据量和算力需求可能没有想象中那么大。
把人类一整年眼中所见拍成每秒30帧的视频,可以装在拇指大小的U盘里。
而1岁儿童只拥有这么多经验数据,已经展现出明显的智能。
如果算法对了,就不需要用整个互联网的数据让AGI去学习。
对于算力需求,他也是用这种直觉式的思维去考虑:人脑的计算能力也有限,远远达不到一个大型算力集群的程度。
比一个服务器节点(node)要大,也比一个机柜(rack)要大,但最大也就再高出一个数量级。
而且随着时间推移,算法会更加高效,所需的算力还会持续下降。

如果说卡马克在3D游戏、火箭和VR,这些看似不搭边的工作领域上有什么共同点,那就是对大型实时反馈系统的优化。
这也是当初Sam Altman邀请他加入OpenAI时看中的地方。
他设想中的AGI架构应该是模块化和分布式的,而不是一个巨大的集中模型。
学习也应该是持续的在线学习,而不是现在的预训练之后大部分参数就不再更新。
我的底线是,如果一个系统不能以30hz的频率运行,也就是训练时33毫秒左右更新一次,我就不会用它。
他进一步表示,作为能自己写原始Cuda代码和能自己管理网络通信的底层系统程序员,可能会去做一些其他人根本不会考虑的工作。
甚至不仅局限于现有的深度学习框架,会尝试更高效的网络架构和计算方法。
总体目标是模拟一个具有内在动机和持续学习能力的虚拟智能体,在虚拟环境中持续学习。
不要机器人,因为制造火箭的经历让他认为打交道的物理对象越少越好。

与卡马克刚涉足AGI不久相比,萨顿在这个问题上已经花费了几十年,他有更具体的研究计划。
虽然这次活动上没有说太多,但主体部分已经以“阿尔伯塔计划”的形式写在一篇arXiv论文里。

阿尔伯塔计划提出了一个统一的智能体框架,强调普遍经验而不是特殊的训练集,关注时间一致性,优先考虑能随算力产生规模效应的方法,以及多智能体交互。
还提出了一个分为12步的路线图。
前6步专注于设计model-free的持续学习方法,后6步引入环境模型和规划。

其中最后一步称为智能增强(Intelligence Amplification),一个智能体可以根据一些通用原则,利用它所学到的知识来放大和增强另一个智能体的行动、感知和认知。
萨顿认为这种增强是充分发挥人工智能潜力的重要组成部分。
在这个过程中,确定评估AI进步的指标非常重要但也十分困难,团队正在探索不同的发展。
另外,卡马克一直是开源的倡导者,但在AGI的问题上他表示会保持一定开放性,但不会全部公开算法细节。
作为一个小团队,卡马克认为需要保持开拓精神,关注长远发展而不是短期利益,
不会过早考虑商业化,没有像ChatGPT这样可以公开发布的中间形态。
对于2030年能做到什么地步,卡马克认为“有可以向公众展示的AGI”,萨顿的表述是“AI原型可以显示出生命迹象(signs of life)”。
2030成关键节点
2030与AGI,并不是第一次同时出现。
顶尖AI团队不约而同都把2030年前后作为实现AGI的关键节点。
比如OpenAI,在拿出20%总算力成立超级智能对齐部门的公告里写着,我们相信超级智能在这个十年段到来。

甚至投资界也出现类似的观点,孙正义刚刚在软银世界企业大会上也拿出来这样一张PPT。

除了OpenAI和Keen Technologies,致力于开发AGI的组织并不多。
OpenAI最大的竞争对手,刚刚拿40亿美元融资的Anthropic,其CEO Dario Amodei在最近一次访谈中提到,两三年内AI能表现得像一个受过良好教育的人类。

Transformer作者Vaswani与Palmer离开谷歌时,创办了AdeptAI,目标也是打造通用智能。
不过目前两人今年初突然离开这家公司,联合创始人中只留下一位David Luan(最右)。

两位Transformer作者另外创办了一家Essential AI,这家公司的愿景就没那么“仰望星空”了,是比较务实的大模型商业化。
国内方面明确喊出AGI目标的同样也不多,主要有MiniMax和杨植麟新创办的月之暗面。
参考链接:
[1]https://www.amii.ca/latest-from-amii/john-carmack-and-rich-sutton-agi/
[2]https://www.youtube.com/watch?v=uTMtGT1RjlY
[3]https://arxiv.org/abs/2208.11173