曲线的谎言
2023-11-15
更新时间:2023-11-15 16:05:27作者:无忧百科

近日,开发者群体正热议一款基于开源模型更换张量(Tensor)名字的话题。研究者认为零一万物近期发布的Yi-34B 模型基本上采用了 LLaMA 的架构,只是重命名了两个张量。
11月6日,零一万物创始人及CEO李开复带队创办的AI 2.0公司零一万物,正式发布首款开源预训练大模型 Yi-34B。此次零一万物开源发布的Yi系列模型,包含34B和6B两个版本。其中开源的Yi-34B模型将发布全球最长、可支持200K 超长上下文窗口(context window)版本,可以处理约40万汉字超长文本输入。
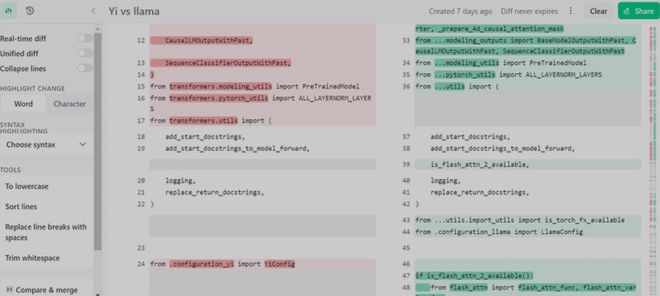
在零一万物Huggingface社区中,有开发者质疑并向零一万物研发团队发去邮件,称除了两个张量(具体是input_layernorm与post_attention_layernorm)被重命名之外,Yi 完全使用了LLaMA的架构。
LLaMA全称为 "Large Language Model Meta AI",是 Meta 创建的大语言模型。今年 7 月,Meta发布了LLaMA2,宣布完全开源,并可免费商用。
针对该质疑邮件,零一研发团队方面进行了回应,回应邮件内容显示“你关于张量(tensor)的观点是正确的,我们也如你所建议的,将对其重命名,从Yi改回LLaMA,零一也将发布改名后的新版本。”
零一研发团队表示,命名问题确实是己方疏忽所致,由于大量训练试验进行重命名,在推出发行版本之前也没有将其改回来,这是己方的错,并表示抱歉造成了混乱。零一团队表示,正在努力加强流程,不会再发生类似失误。
行外人关注大模型的点在于是否有原创性,对开发者而言,更关注的是大模型的适配工作。
研究人士在帖子中称,“Yi的代码更改并没有通过Pull Request(GitHub开发者社区代码提交术语)的方式提交到Transformers项目中,而是以外部代码的形式附加上去,这可能存在安全风险或不被框架所支持的问题。HuggingFace排行榜甚至不会对这个上下文窗口最高可达200K的模型进行基准测试,因为其没有自定义代码策略。零一声称其是32K模型,但被配置为4K模型,没有RoPE伸缩配置,也没有解释如何伸缩。”
11月14日,阿里巴巴前副总裁、AI框架领域专家贾扬清发朋友圈感慨做小公司不容易,希望国内企业如果是开源的模型结构,不要改换名字,以免令他人为其多做适配工作。他也提到,有厂商的新模型实际就是LLaMA架构,但为了显得不一样,将代码里的名字从LLaMA改成了自己的名字,并换了几个变量名,但未提及具体厂商姓名。
对于Yi大模型对张量的更名,零一万物方面对第一财经记者回应称:GPT是一个业内公认的成熟架构,LLaMA在GPT上做了总结。零一万物研发大模型的结构设计基于GPT成熟结构,借鉴了行业顶尖水平的公开成果,由于大模型技术发展还在非常初期,与行业主流保持一致的结构,更有利于整体的适配与未来的迭代。同时基于零一万物团队对模型和训练的理解做了大量工作,也在持续探索模型结构层面本质上的突破。

零一方面称,模型结构仅是模型训练其中一部分。Yi 开源模型在其他方面的精力,比如数据工程、训练方法、baby sitting(训练过程监测)的技巧、hyper parameter设置、评估方法以及对评估指标的本质理解深度、对模型泛化能力的原理的研究深度、在AI infra(基础设施)方面的能力等,投入了大量研发和打底工作,这些工作往往比起基本结构能起到更大的作用跟价值,这些也是零一万物在大模型预训练阶段的核心技术护城河。
当模型架构渐成行业通用,商用授权保护也越来越多引起关注。零一方面告诉记者,商用授权保护的是LLaMA的参数,Yi 开源模型从零开始训练,其模型参数和参数获得过程和LLaMA无关,故不需要商用授权。
行业人士认为,Yi模型的开发初衷实际是为了应对国内无法访问OpenAI与谷歌大模型的障碍,开发针对中国市场以及中文语言环境的LLM(Large Language Model,大语言模型)生态,让开发者轻松使用其LLM应用程序。
一位人工智能领域专家对记者表示,开源本身是非常有意义的,但基于开源从事大模型研发工作,他并不看好国内创业公司的未来,在其看来国内大模型更大机会在于资金充沛的大公司,但小公司密集涌入竞争的好处,在于为行业培养了更多人工智能与大语言模型领域的人才。未来国内赛道更大的机会还是在应用层方面。